TLDR
Rion Williams wrote the theory on four Flink enrichment strategies. I built the runnable SQL for Confluent Cloud, where a few things work differently than open-source Flink (no PROCTIME(), no JDBC lookup joins).
External enrichment uses a regular LEFT JOIN against a compacted Kafka topic. Gradual enrichment uses an event-time temporal join that gives you version-correct customer data per order. Both run as pure Flink SQL on Confluent Cloud.
I published a Flink SQL skill on the Tessl registry that generates these queries for you. Pair it with mcp-confluent and your AI assistant can write the SQL, create the topics, and submit the Flink statements without you leaving the editor.
Rion Wrote the Playbook, I Wanted the Code
Rion Williams published a post in January that laid out four enrichment strategies for Apache Flink: external enrichment, gradual enrichment, two-phase bootstrapping, and gated enrichment. The post is excellent and you should read it. It explains why per-record API calls fall apart under load, how CDC streams can pre-populate Flink state, and when you need a dedicated bootstrap job for correctness guarantees.
What the post doesn’t include is runnable code.
I wanted to see these strategies work on Confluent Cloud, where a few things are different from open-source Flink.
Confluent Cloud’s Flink dialect doesn’t support PROCTIME(), and there’s no JDBC connector for lookup joins.
Those two gaps mean the textbook SQL from the Flink docs doesn’t copy-paste into a Confluent Cloud Flink shell.
So I built the demos: four working implementations in the flink-sql-skill repo, two in pure SQL and two in Java with the Table API. This post focuses on the two SQL strategies. The Java ones get a teaser at the end.
The Setup: Orders Meet Customers
Every demo uses the same scenario.
An orders stream carries purchase events with a customer_id.
A customers table has the profile data you need: name, tier, country.
The goal is to produce an enriched orders stream where every order includes the customer’s profile.
Here are the shared tables that all four demos use:
-- Source: append-only order events
CREATE TABLE enrich_demo_orders (
order_id STRING NOT NULL,
customer_id STRING NOT NULL,
amount DECIMAL(10, 2),
order_time TIMESTAMP_LTZ(3),
WATERMARK FOR order_time AS order_time - INTERVAL '5' SECOND
) DISTRIBUTED BY HASH(order_id) INTO 1 BUCKETS
WITH ('changelog.mode' = 'append');
-- Enrichment: compacted customer profiles (for external enrichment)
CREATE TABLE enrich_demo_customers_ref (
customer_id STRING NOT NULL,
name STRING,
tier STRING,
country STRING,
PRIMARY KEY (customer_id) NOT ENFORCED
) DISTRIBUTED BY HASH(customer_id) INTO 1 BUCKETS
WITH ('changelog.mode' = 'upsert', 'kafka.cleanup-policy' = 'compact');
-- Enrichment: versioned CDC stream (for gradual enrichment)
CREATE TABLE enrich_demo_customers_cdc (
customer_id STRING NOT NULL,
name STRING,
tier STRING,
country STRING,
updated_at TIMESTAMP_LTZ(3),
PRIMARY KEY (customer_id) NOT ENFORCED,
WATERMARK FOR updated_at AS updated_at - INTERVAL '5' SECOND
) DISTRIBUTED BY HASH(customer_id) INTO 1 BUCKETS
WITH ('changelog.mode' = 'upsert', 'kafka.cleanup-policy' = 'compact');On Confluent Cloud, CREATE TABLE automatically provisions the backing Kafka topic.
No separate topic creation step needed.
Strategy 1: External Enrichment
Rion’s description: issue a per-record lookup against an external source, optionally caching in state.
On open-source Flink, you’d use a lookup join with FOR SYSTEM_TIME AS OF PROCTIME().
On Confluent Cloud, that doesn’t work.
PROCTIME() isn’t supported in the Confluent Flink dialect, and there’s no JDBC connector.
The workaround is a regular LEFT JOIN against a compacted Kafka topic that Flink treats as a dynamic table holding current state.
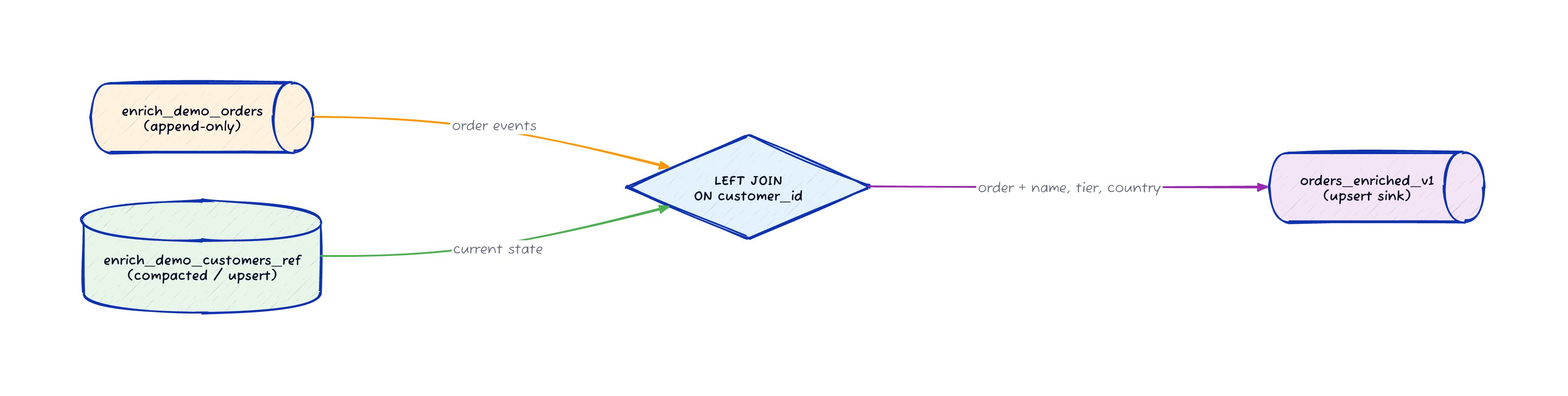
INSERT INTO enrich_demo_orders_enriched_v1
SELECT
o.order_id,
o.customer_id,
c.name AS customer_name,
c.tier,
c.country,
o.amount,
o.order_time
FROM enrich_demo_orders o
LEFT JOIN enrich_demo_customers_ref c
ON o.customer_id = c.customer_id;The join operator holds the current state of the compacted customer topic in memory. When an order arrives, Flink looks up the customer by key and emits the enriched record.
There’s a side effect worth knowing about.
Because the customer table can change (a customer upgrades from SILVER to GOLD), the output becomes a changelog stream with retracts and updates.
That means the sink table needs a PRIMARY KEY and changelog.mode = 'upsert'.
| If the difference between append mode and upsert mode isn’t clear, I wrote a separate post about changelog streams and table-stream duality. selectstar.stream has interactive visualizations that show how each changelog type works. |
This strategy works well when you don’t care about which version of the customer profile the order joined against. You always get the latest. For low-volume use cases or when staleness is acceptable, this is the simplest option.
Strategy 2: Gradual Enrichment
Rion’s description: a CDC stream continuously feeds enrichment data into Flink state, and source events join against a progressively populated cache. The key difference from external enrichment is that gradual enrichment is version-aware.
On Confluent Cloud, the implementation uses an event-time temporal join with FOR SYSTEM_TIME AS OF o.order_time.
Flink looks up the version of the customer that was valid at the moment the order was placed.
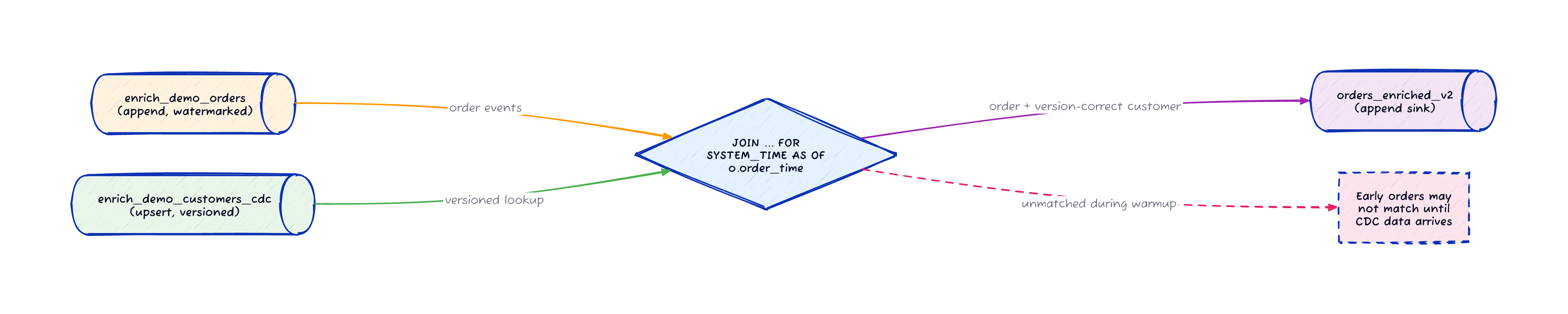
INSERT INTO enrich_demo_orders_enriched_v2
SELECT
o.order_id,
o.customer_id,
c.name AS customer_name,
c.tier,
c.country,
o.amount,
o.order_time,
c.updated_at AS customer_version_time
FROM enrich_demo_orders o
JOIN enrich_demo_customers_cdc
FOR SYSTEM_TIME AS OF o.order_time AS c
ON o.customer_id = c.customer_id;This SQL does something specific.
If customer c-002 changes tier from SILVER to GOLD at 10:05:00, an order placed at 10:02:00 joins against SILVER and an order placed at 10:06:00 joins against GOLD.
The customer_version_time column in the output lets you verify which version each order matched.
The tradeoff is the warmup gap. When the job starts, the CDC table is empty. Orders that arrive before their corresponding customer CDC records will not match. If you use an INNER JOIN (the default in this demo), those early orders are dropped. Switching to a LEFT JOIN passes them through with NULL customer fields instead.
For most production use cases where eventual consistency is acceptable, this is the right strategy. The version correctness is the feature that external enrichment doesn’t give you.
What’s Next: Bootstrap and Gated Enrichment
The remaining two strategies require Java and the Table API.
Two-phase bootstrapping (Demo 3) runs a dedicated bootstrap job that consumes the full customer snapshot before the main enrichment job starts. On Confluent Cloud, this replaces the State Processor API savepoint pattern from Rion’s article with statement lifecycle orchestration: you submit the bootstrap statement, wait for it to complete, then submit the live enrichment statement. The correctness guarantee is the same, and the SQL is simpler because Confluent Cloud manages the state handoff.
Gated enrichment (Demo 4) uses a Process Table Function (PTF) that buffers incoming orders until a gate signal indicates the enrichment state is fully loaded. This is the strategy Rion described as "discussed far more often than successfully implemented." The implementation uses a custom PTF with explicit state management and a signal topic that controls when the gate opens.
Both demos are in the repo with step-by-step instructions. I’ll cover them in a follow-up post once I’ve run them through more edge cases on Confluent Cloud.
The Agentic Workflow: Skill + MCP
Here’s where it gets interesting. I published a Flink SQL skill on the Tessl registry that knows Confluent Cloud’s Flink dialect, including the workarounds for PROCTIME() and the DISTRIBUTED BY syntax that open-source Flink doesn’t use.
Install it into Claude Code or Cursor:
npx tessl i gamussa/flink-sqlThe skill generates correct Flink SQL for Confluent Cloud. But generating SQL is half the job. You also need to create the Kafka topics, submit the Flink statements, and verify the results.
That’s where mcp-confluent comes in. The Confluent MCP server exposes 50+ tools that let your AI assistant interact with Confluent Cloud directly: create topics, submit Flink SQL statements, produce test data, consume results, manage connectors.
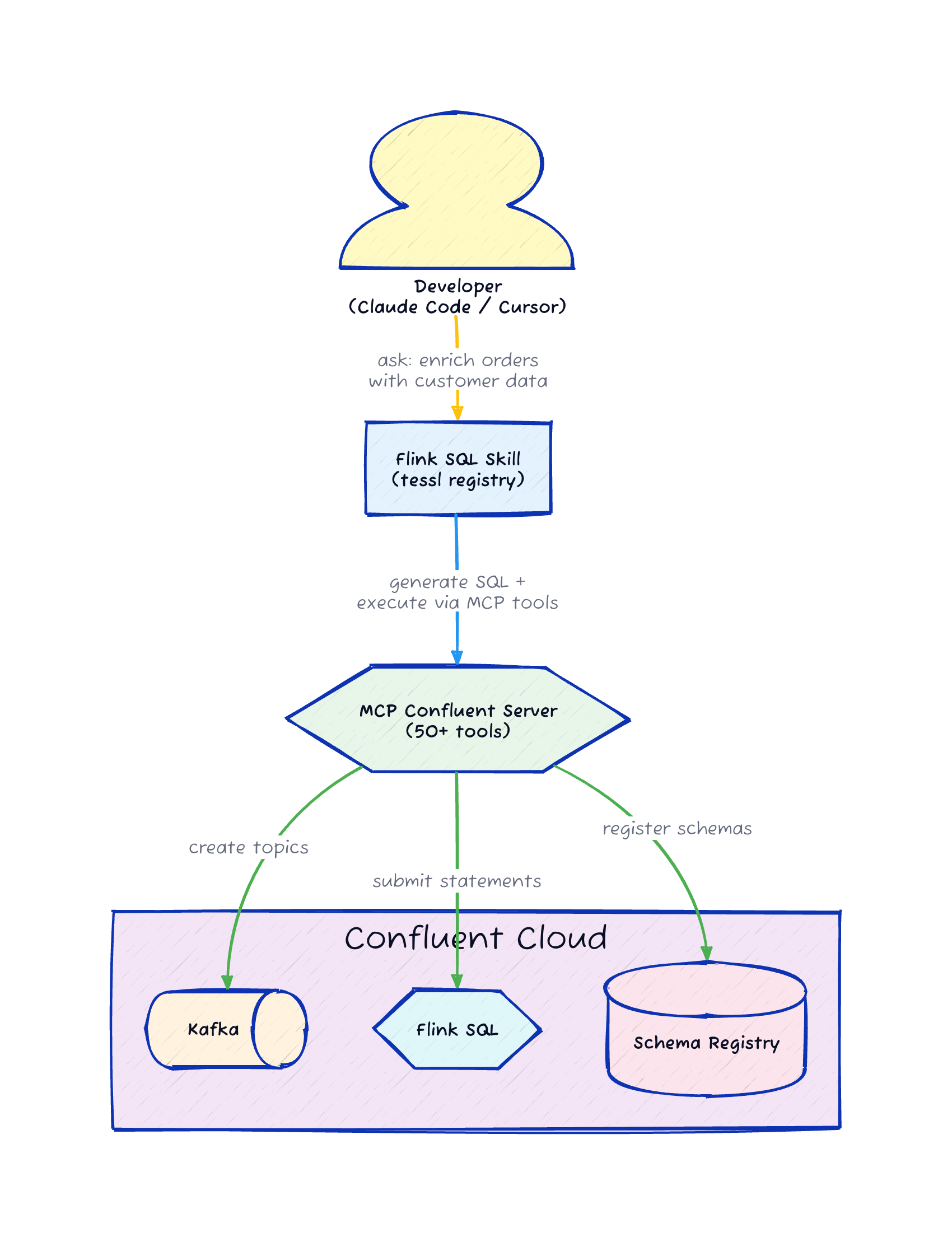
When you combine the two, you get a workflow where you describe what you want in natural language ("enrich orders with customer profiles using a temporal join"), the skill generates the SQL, and the MCP server creates the topics and submits the statements. You stay in your editor the whole time.
I built these enrichment demos with exactly this workflow. The skill handled the SQL generation including the Confluent Cloud-specific syntax, and mcp-confluent handled the deployment. The quality score on the skill is 92% on the Tessl registry, which means the SQL it generates passes validation against the Confluent Cloud Flink parser consistently.
Try It
The enrichment demos are at github.com/gAmUssA/flink-sql-skill/demos/enrichment-strategies. You need a Confluent Cloud environment with a Flink compute pool and a Kafka cluster in the same region.
To install the skill and start generating Flink SQL:
npx tessl i gamussa/flink-sqlRead Rion’s original post for the theory: Prepare for Launch: Enrichment Strategies for Apache Flink.
If you hit issues with the demos or the skill, open a GitHub issue.