Streaming Movies Ratings with Kafka Streams and KSQL
Written by Viktor Gamov -

The sole purpose of this blog post is to draft a playbook for my presentation «Crossing the streams: Rethinking Stream processing with Kafka Streams and KSQL» [1] that I recently did on Kafka Summit 2018 in San Francisco.
A full source code published in confluetninc/demo-scene repository [2]
| Version | Date | Comments |
|---|---|---|
v1.2 |
01/17/2019 |
use CP 5.1.0, updated Control Center screenshots |
v1.1 |
11/21/2018 |
Fixed links and minor grammar |
v1.0 |
11/20/2018 |
Initial revision |
| Disclaimer: Another goal is to exercise some ideas around the visual representation of posts in this blog. And third and the last goal is to brush up my technical writing skills! Since I moved to DevX [3] from Professional Services where I did write a truckload of customer engagement reports. |
Prerequisites
-
Confluent Platform Enterprise 5.x [4]
-
download it
-
unizip to any folder
-
add folder to
PATHvariableexport CONFLUENT_PLATFORM_VERSION=5.1.0 export CONFLUENT_HOME=~/projects/confluent/confluent-ent/$CONFLUENT_PLATFORM_VERSION export PATH=$CONFLUENT_HOME/bin:$PATH alias cnfl="confluent" (1)1 a neat little alias that can save few symbols to type
-
-
Get example from GitHub
-
If you will follow steps below you should checkout only directory that has source code relevant to this post.
mkdir ~/temp/demo-scene cd ~/temp/demo-scene git init . git remote add origin -f https://github.com/confluentinc/demo-scene/ git config core.sparsecheckout true echo "streams-movie-demo/*" >> .git/info/sparse-checkout git pull --depth=2 origin master cd streams-movie-demo ls -lhand you should see something like this
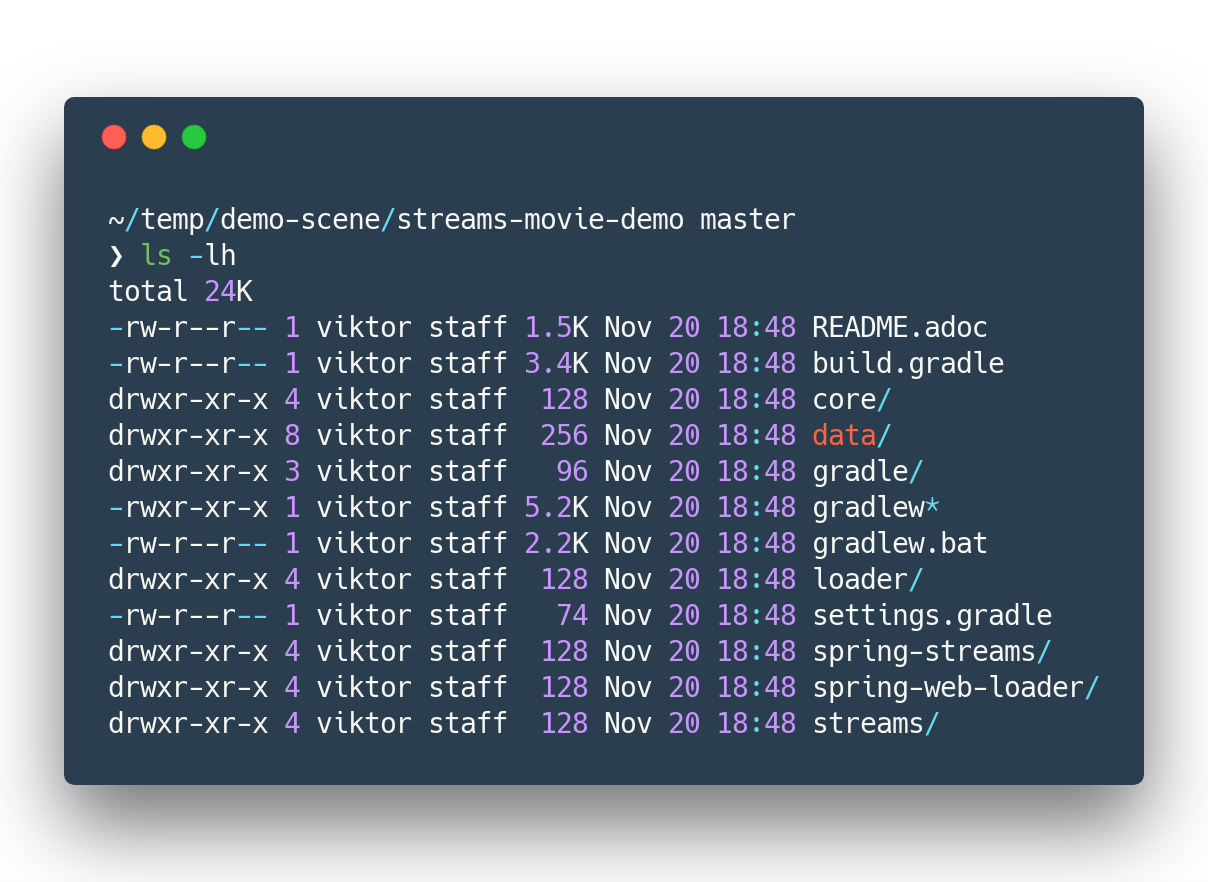 Figure 1. The output of
Figure 1. The output ofls -lh streams-movie-demo
-
Demo playbook
Let’s start Confluent platform, create topics and populate with some data
Start Confluent Platform
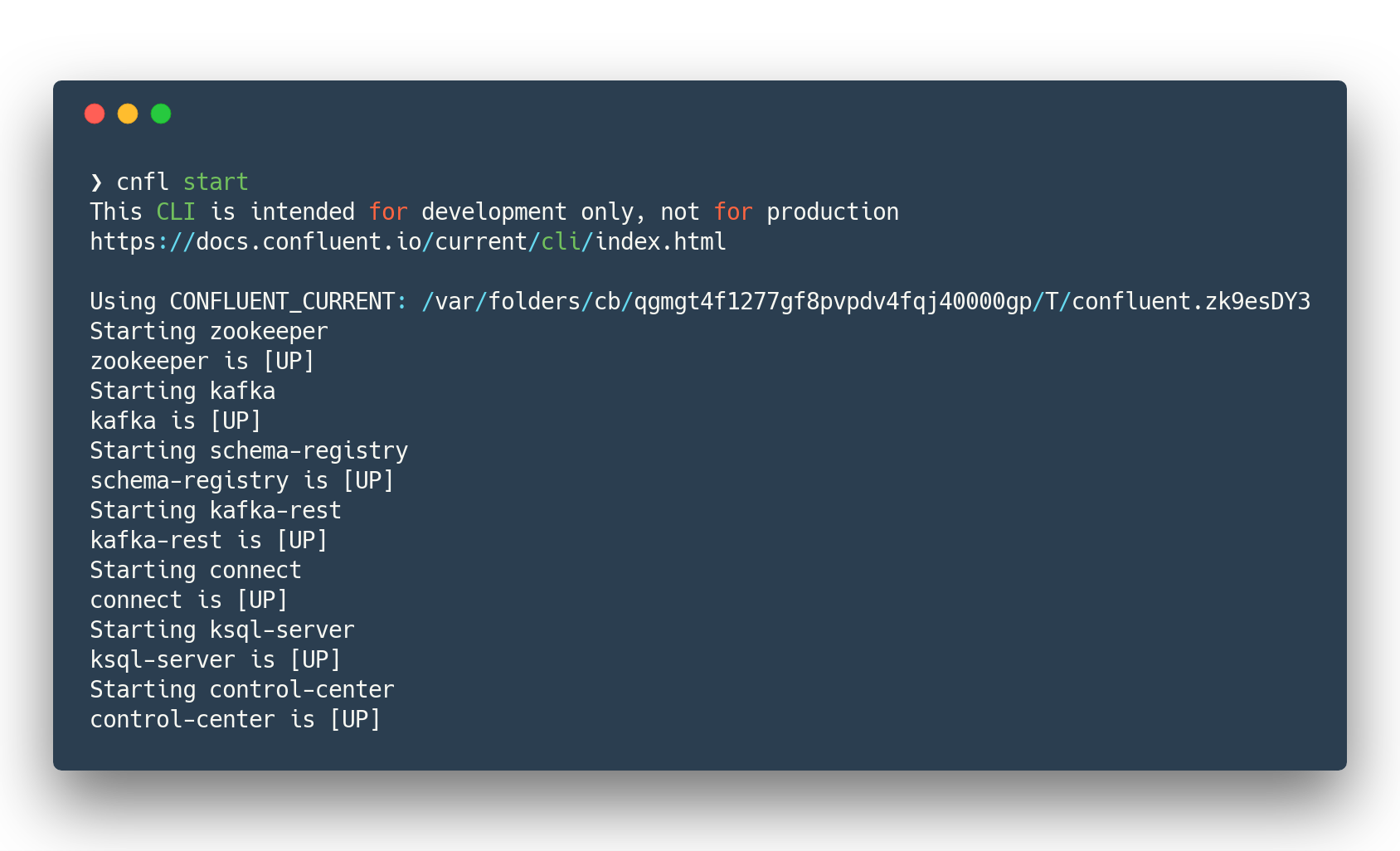
cnfl destroy (1)
cnfl start (2)
echo "auto.offset.reset=earliest" >> $CONFLUENT_HOME/etc/ksql/ksql-server.properties (3)| 1 | Make sure that there is no leftovers data |
| 2 | Start confluent platform. May take up to minute to start all components. |
| 3 | This will allow KSQL queries to read all data |
Populate Movies and Rating Information
cd data/
cat movies.dat | kafka-console-producer --broker-list localhost:9092 --topic raw-movies (1)
cat ratings.dat | kafka-console-producer --broker-list localhost:9092 --topic raw-ratings (2)| 1 | Source topic for movies - raw-movies |
| 2 | Source topic for ratings - raw-ratings |
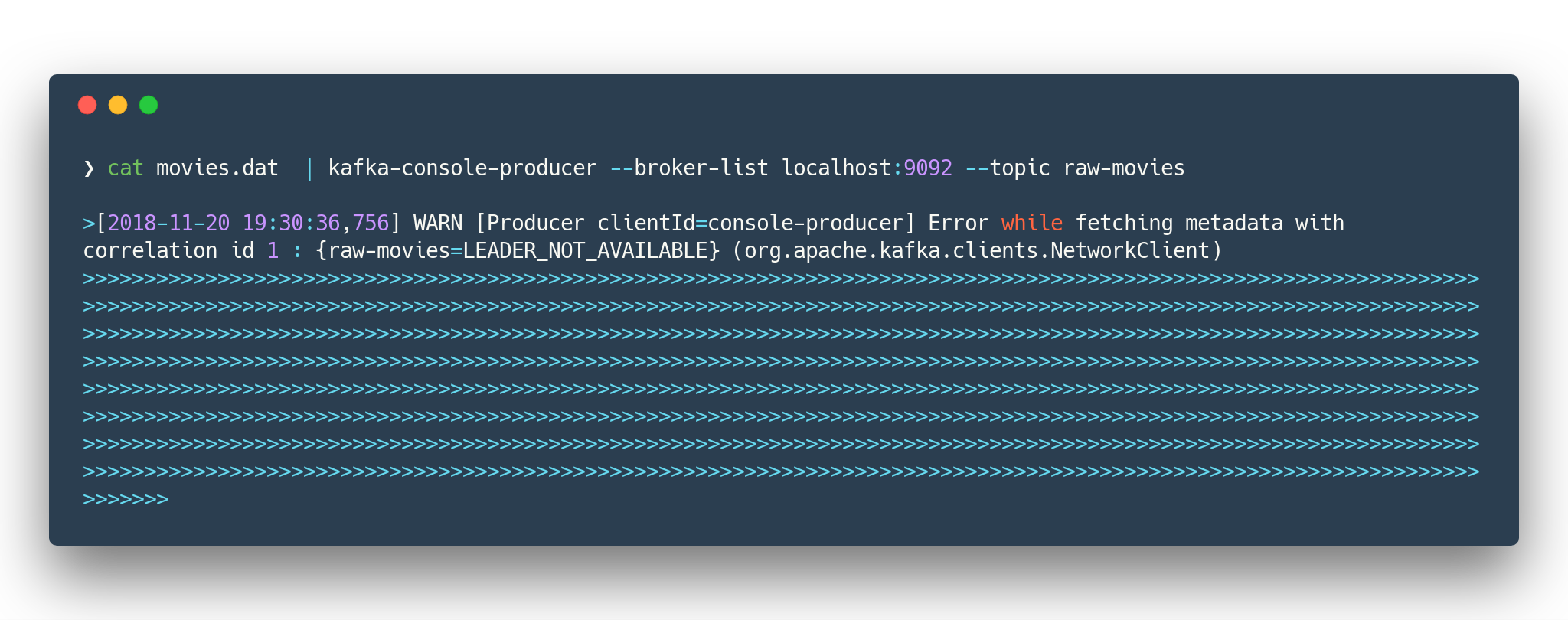
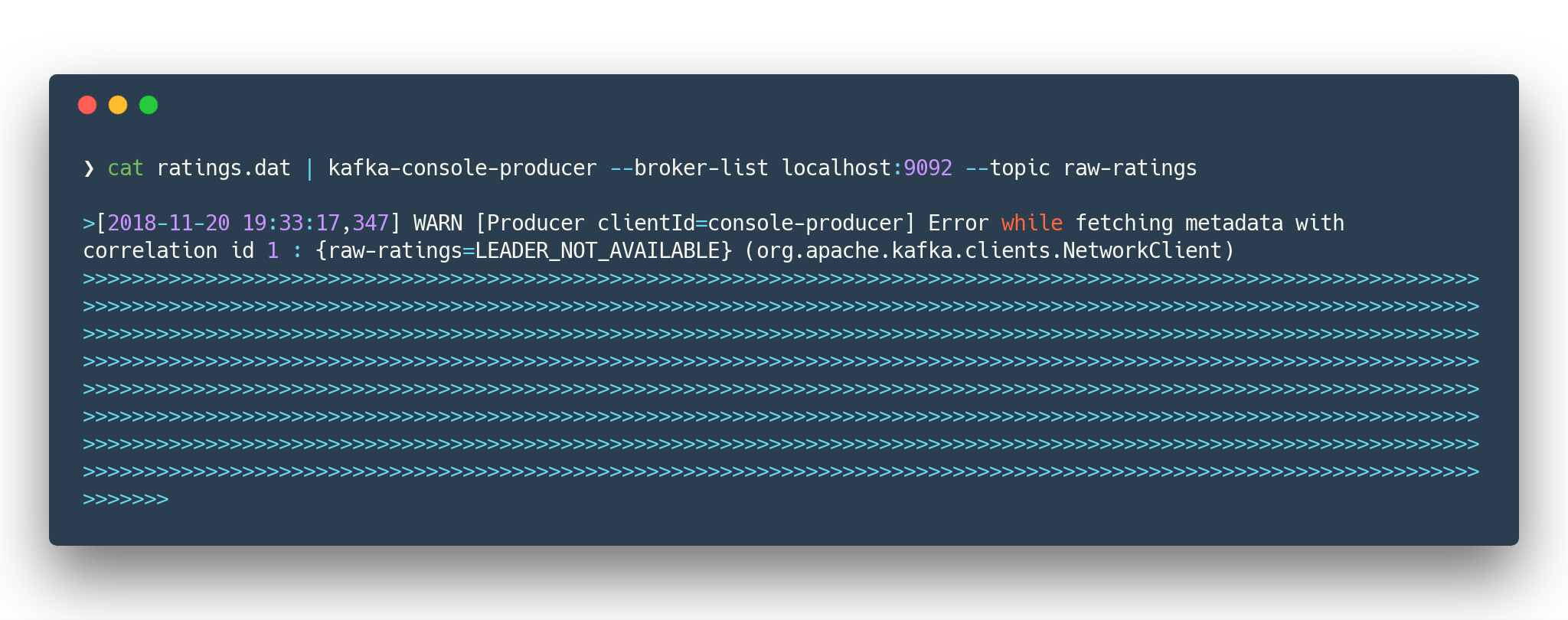
The warnings like WARN [Producer clientId=console-producer] Error while fetching metadata with correlation id 1 : {raw-movies=LEADER_NOT_AVAILABLE} (org.apache.kafka.clients.NetworkClient) and WARN [Producer clientId=console-producer] Error while fetching metadata with correlation id 1 : {raw-ratings=LEADER_NOT_AVAILABLE} (org.apache.kafka.clients.NetworkClient) are absolutely normal.
Topics raw-movies and raw-ratings not created when we started producing messages to it.
And because by default Apache Kafka allows automatic topic creation ( The parameter auto.create.topics.enable in configuration [5] topics created.
|
Create the destination topics
# enable compaction for this topics
$CONFLUENT_HOME/bin/kafka-topics --create --zookeeper localhost:2181 --replication-factor 1 --partitions 1 --config cleanup.policy=compact --topic movies
$CONFLUENT_HOME/bin/kafka-topics --create --zookeeper localhost:2181 --replication-factor 1 --partitions 1 --config cleanup.policy=compact --topic rating-sums
$CONFLUENT_HOME/bin/kafka-topics --create --zookeeper localhost:2181 --replication-factor 1 --partitions 1 --config cleanup.policy=compact --topic rating-counts
$CONFLUENT_HOME/bin/kafka-topics --create --zookeeper localhost:2181 --replication-factor 1 --partitions 1 --config cleanup.policy=compact --topic rating-averages
$CONFLUENT_HOME/bin/kafka-topics --create --zookeeper localhost:2181 --replication-factor 1 --partitions 1 --config cleanup.policy=compact --topic rated-movies
Generate test load
-
Start raw rating generator
./gradlew loader:streamWithRawRatingStreamerOr if you have groovy installed./gradlew loader:build (1) groovy -cp "./loader/build/libs/loader.jar" \ loader/src/main/groovy/RawRatingStreamer.groovy "localhost:9092" (2)1 build loader.jarfirst. This is «fat jar» that has all required dependencies (Kafka client libraries, serializers, etc)2 run raw ratings generator script I recommend to run the raw rating generator in a separate terminal window so you can interrupt it with Ctrl+C
Consume result with KSQL UI in Control Center
-
load page from http://localhost:9021
-
open KSQL panel and switch to «Query Editor.»
CREATE TABLE RATED_MOVIES \ (MOVIE_ID BIGINT,\ TITLE VARCHAR,\ RELEASE_YEAR BIGINT,\ RATING DOUBLE)\ WITH (KAFKA_TOPIC='rated-movies',VALUE_FORMAT='AVRO', KEY = 'movie_id'); (1) select TITLE, RATING from RATED_MOVIES where MOVIE_ID=362; (2)1 Create a table with Movie ratings 2 Find rating for Lethal Weapon ( movie_id=362)
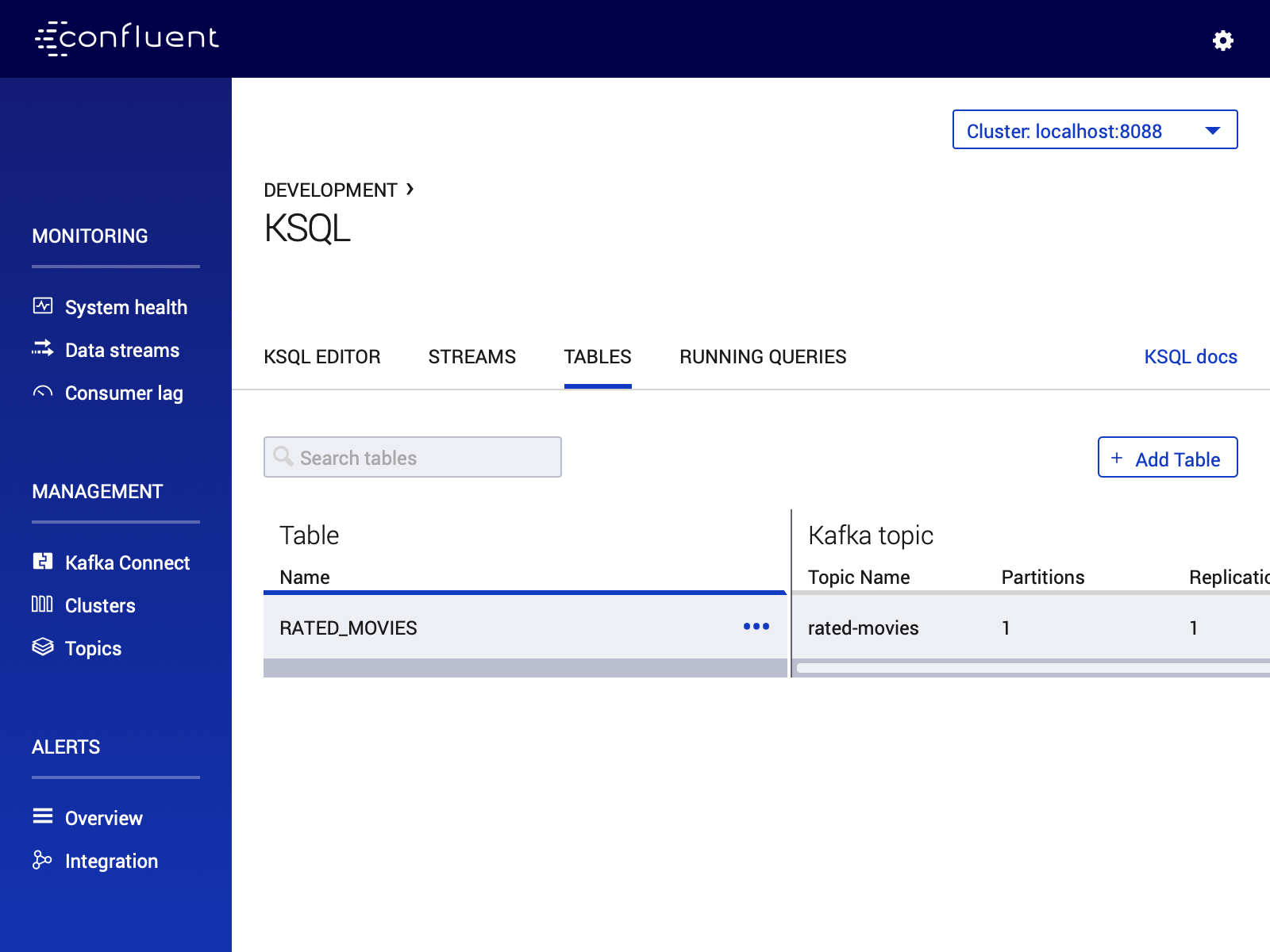
RATED_MOVIES table is registered in KSQL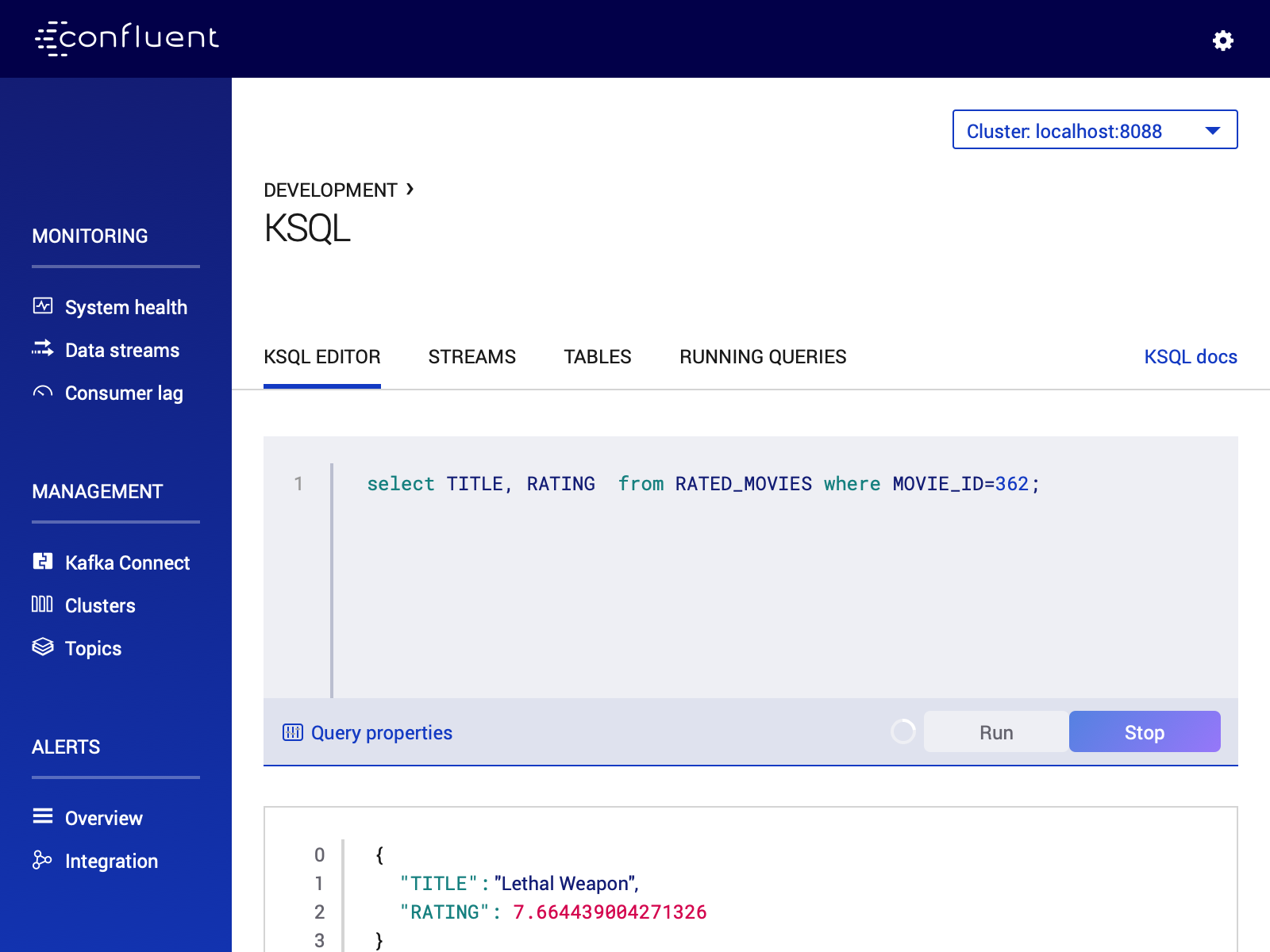
RATED_MOVIES table for the rating of «Lethal Weapon» movie