Learn how to build event-driven microservices with Apache Kafka, Kotlin, and Ktor
Written by Viktor Gamov <viktor@confluent.io>, Anton Arhipov <anton@jetbrains.com> -
How can I implement an average aggregation that implements incremental functions, namely count and sum?
Kafka Streams natively supports incremental aggregation functions, in which the aggregation result is updated based on the values captured by each window.
Incremental functions include count, sum, min, and max.
An average aggregation cannot be computed incrementally.
However, as this tutorial shows, it can be implemented by composing incremental functions, namely count and sum.
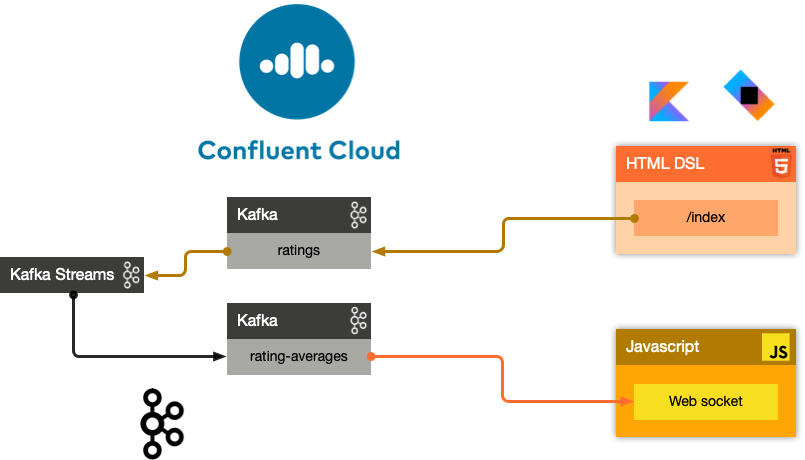
Consider a topic with events that represent ratings of movies.
In this tutorial, we’ll write a program that calculates and maintains a running average rating for each movie.
Prerequisites
Ensure you install the following toolset on your computer:
-
You should have your login and password information handy after you sign up for Confluent Cloud. The ccloudinit script will ask you for your login information. -
Docker (If you want to run locally)
-
Git
-
Your favorite IDE or text editor
-
Personally, I recommend IntelliJ IDEA.
-
Tutorial
To get started, make a new directory anywhere you’d like for this project:
First, create a Kotlin project with Kotlin DSL
Gradle build
import org.jetbrains.kotlin.gradle.dsl.Coroutines
import org.jetbrains.kotlin.gradle.tasks.KotlinCompile
val logback_version: String by project
val ktor_version: String by project
val kotlin_version: String by project
val confluent_version: String by project
val ak_version: String by project
plugins {
application
kotlin("jvm") version "1.4.30"
}
group = "com.example"
version = "0.0.1-SNAPSHOT"
application {
mainClassName = "io.ktor.server.netty.EngineMain"
}
repositories {
mavenLocal()
jcenter()
maven ("https://packages.confluent.io/maven")
maven ("https://kotlin.bintray.com/ktor")
maven ("https://jitpack.io")
}
dependencies {
implementation("org.apache.kafka:kafka-streams:2.7.0")
implementation("io.confluent:kafka-json-schema-serializer:$confluent_version")
implementation("io.confluent:kafka-streams-json-schema-serde:$confluent_version") {
exclude("org.apache.kafka", "kafka-clients")
}
implementation("org.jetbrains.kotlin:kotlin-stdlib-jdk8:$kotlin_version")
implementation("io.ktor:ktor-server-netty:$ktor_version")
implementation("ch.qos.logback:logback-classic:$logback_version")
implementation("io.ktor:ktor-server-core:$ktor_version")
implementation("io.ktor:ktor-html-builder:$ktor_version")
implementation("io.ktor:ktor-server-host-common:$ktor_version")
implementation("io.ktor:ktor-jackson:$ktor_version")
implementation("io.ktor:ktor-websockets:$ktor_version")
implementation("com.github.gAmUssA:ktor-kafka:1913118fb3")
testImplementation("io.ktor:ktor-server-tests:$ktor_version")
testImplementation("org.apache.kafka:kafka-streams-test-utils:$ak_version")
}
tasks.withType<KotlinCompile>().configureEach {
kotlinOptions.jvmTarget = "1.8"
}kotlin.code.style=official org.gradle.parallel=true org.gradle.caching=true ktor_version=1.5.2 logback_version=1.2.1 kotlin_version=1.4.30 confluent_version=6.1.1 ak_version=2.7.0
Config files
ktor {
development = true
deployment {
port = 8080
port = ${?PORT}
}
application {
modules = [
io.confluent.developer.ApplicationKt.module,
io.confluent.developer.kstreams.RunningAverageKt.module
]
}
}ktor {
kafka {
# Required connection configs for Kafka producer, consumer, and admin
bootstrap.servers = ["server"]
properties {
security.protocol = SASL_SSL
sasl.jaas.config = "org.apache.kafka.common.security.plain.PlainLoginModule required username='user' password='password';"
sasl.mechanism = PLAIN
# Required for correctness in Apache Kafka clients prior to 2.6
client.dns.lookup = use_all_dns_ips
# Best practice for Kafka producer to prevent data loss
acks = all
# Required connection configs for Confluent Cloud Schema Registry
schema.registry.url = "sr_url"
basic.auth.credentials.source = USER_INFO
basic.auth.user.info = "key:pass"
}
consumer {
group.id = "ktor-consumer"
key.deserializer = org.apache.kafka.common.serialization.LongDeserializer
value.deserializer = org.apache.kafka.common.serialization.DoubleDeserializer
}
producer {
client.id = "ktor-producer"
key.serializer = org.apache.kafka.common.serialization.LongSerializer
value.serializer = io.confluent.kafka.serializers.json.KafkaJsonSchemaSerializer
}
streams {
application.id = "ktor-stream"
# TODO: cloud should be 3
replication.factor = 3
//cache.max.size.buffering = 1024
cache.max.bytes.buffering = 0
default.topic.replication.factor = 3
//default.key.serde
//default.value.serde
}
}
}Web application
First, we create a view code that renders the UI using the kotlinx.html library. create the following file at /src/main/kotlin/io/confluent/developer/Html.kt.
package io.confluent.developer
import kotlinx.html.*
import kotlinx.html.dom.createHTMLDocument
import org.w3c.dom.Document
object Html {
class TEMPLATE(consumer: TagConsumer<*>) :
HTMLTag(
"template", consumer, emptyMap(),
inlineTag = true,
emptyTag = false
), HtmlInlineTag
fun FlowContent.template(block: TEMPLATE.() -> Unit = {}) {
TEMPLATE(consumer).visit(block)
}
fun TEMPLATE.li(classes: String? = null, block: LI.() -> Unit = {}) {
LI(attributesMapOf("class", classes), consumer).visit(block)
}
fun page(js: String, content: FlowContent.() -> Unit = {}): HTML.() -> Unit = {
head {
css("https://cdn.jsdelivr.net/npm/bootstrap@4.6.0/dist/css/bootstrap.min.css")
css("https://maxcdn.bootstrapcdn.com/font-awesome/4.7.0/css/font-awesome.min.css")
js("https://code.jquery.com/jquery-3.5.1.slim.min.js")
js("https://cdn.jsdelivr.net/npm/bootstrap@4.6.0/dist/js/bootstrap.bundle.min.js")
js("/assets/$js")
title("Ktor Kafka App")
}
body {
div("container rounded") {
content()
}
}
}
val indexHTML = page("index.js") {
val movies = mapOf(
362 to "Lethal Weapon",
363 to "Guardians of the Galaxy",
364 to "Se7en"
)
div("row") {
form(
action = "/rating",
method = FormMethod.post
) {
name = "myform"
id = "myform"
div("form-group row") {
label("col-4 col-form-label") {
htmlFor = "movieId"
+"Movie Title"
}
div("col-8") {
select("custom-select") {
name = "movieId"
id = "movieId"
for ((k, v) in movies) {
option {
value = k.toString()
+v
}
}
}
}
}
div("form-group row") {
label("col-4 col-form-label") {
htmlFor = "rating"
+"Rating"
}
div("col-8") {
select("custom-select") {
name = "rating"
id = "rating"
for (n in 10 downTo 1) {
option {
value = n.toString()
+"$n"
}
}
}
}
}
div("form-group row") {
div("offset-4 col-8") {
button(classes = "btn btn-primary", type = ButtonType.submit, name = "submit") {
+"Submit"
}
}
}
}
}
div("container") {
id = "myAlert"
div("alert alert-success alert-dismissible hide") {
id = "myAlert2"
role = "alert"
+"Thank you for submitting your rating"
button(type = ButtonType.button, classes = "close") {
attributes["data-dismiss"] = "alert"
span {
+"x"
}
}
}
}
}
val index: Document = createHTMLDocument().html(block = indexHTML)
fun HEAD.css(source: String) {
link(source, LinkRel.stylesheet)
}
fun HEAD.js(source: String) {
script(ScriptType.textJavaScript) {
src = source
}
}
}There’s some JavaScript that we need to include for this HTML thingy to work properly.
Let’s add the following file: /src/main/resources/META-INF/resources/assets/index.js with the content’s as provided below:
const wsProto = (window.location.protocol === 'https:') ? 'wss:' : 'ws:';
const wsBase = `${wsProto}//${window.location.hostname}:${window.location.port}`;
window.onload = function () {
$(".alert").hide()
let myForm = document.getElementById('myform');
myForm.addEventListener('submit', function (event) {
event.preventDefault();
let formData = new FormData(myForm), result = {};
for (let entry of formData.entries()) {
result[entry[0]] = entry[1];
}
result = JSON.stringify(result)
// console.log(result);
let xhr = new XMLHttpRequest();
xhr.open(myForm.method, myForm.action, true);
xhr.setRequestHeader('Content-Type', 'application/json; charset=UTF-8');
xhr.send(result);
$(".alert").show()
});
let ws = new WebSocket(`${wsBase}/kafka`);
ws.onmessage = function (event) {
let data = JSON.parse(event.data);
console.log(data)
};
}First, we set up a form listener to send the movie ratings to the web application. And secondly there’s a WebSocket channel that we open in order to receive the data from the backend.
Let’s build the application backend now. Create the following file at /src/main/kotlin/io/confluent/developer/Application.kt.
import com.typesafe.config.Config
import com.typesafe.config.ConfigFactory.parseFile
import io.confluent.developer.Html.indexHTML
import io.confluent.developer.kstreams.Rating
import io.confluent.developer.kstreams.ratingTopicName
import io.confluent.developer.kstreams.ratingsAvgTopicName
import io.confluent.developer.ktor.buildProducer
import io.confluent.developer.ktor.createKafkaConsumer
import io.confluent.developer.ktor.send
import io.ktor.application.*
import io.ktor.features.*
import io.ktor.html.*
import io.ktor.http.*
import io.ktor.http.cio.websocket.*
import io.ktor.http.content.*
import io.ktor.jackson.*
import io.ktor.request.*
import io.ktor.response.*
import io.ktor.routing.*
import io.ktor.server.netty.*
import io.ktor.websocket.*
import org.apache.kafka.clients.consumer.KafkaConsumer
import org.apache.kafka.clients.producer.KafkaProducer
import java.io.File
import java.time.Duration
fun main(args: Array<String>): Unit = EngineMain.main(args)
fun Application.module(testing: Boolean = false) {
//https://youtrack.jetbrains.com/issue/KTOR-2318
val kafkaConfigPath = "src/main/resources/kafka.conf"
install(ContentNegotiation) {
jackson()
}
val config: Config = parseFile(File(kafkaConfigPath))
val producer: KafkaProducer<Long, Rating> = buildProducer(config)
install(WebSockets)
routing {
//region static assets location
static("/assets") {
resources("META-INF/resources/assets")
}
//endregion
post("rating") {
val rating = call.receive<Rating>()
producer.send(ratingTopicName, rating.movieId, rating)
data class Status(val message: String)
call.respond(HttpStatusCode.Accepted, Status("Accepted"))
}
webSocket("/kafka") {
val consumer: KafkaConsumer<Long, Double> = createKafkaConsumer(config, ratingsAvgTopicName)
try {
while (true) {
consumer.poll(Duration.ofMillis(100))
.forEach {
outgoing.send(
Frame.Text(
"""{
"movieId":${it.key()},
"rating":${it.value()}
}
""".trimIndent()
)
)
}
}
} finally {
consumer.apply {
unsubscribe()
//close()
}
log.info("consumer for ${consumer.groupMetadata().groupId()} unsubscribed and closed...")
}
}
get("/") {
call.respondHtml(
HttpStatusCode.OK,
indexHTML
)
}
}
}Data classes
Create a data class file at src/main/kotlin/io/confluent/developer/kstreams/Rating.kt for the stream of ratings:
data class Rating(val movieId: Long = 1L, val rating: Double = 0.0)Next, create data class file in src/main/kotlin/io/confluent/developer/kstreams/Rating.kt for the pair of counts and sums:
data class CountAndSum(var count: Long = 0L, var sum: Double = 0.0)
We’re going to use this record to store intermediate results.
The reason why we’re using json schema support in Schema Registry for this is that we can use KafkaJsonSchemaSerde to handle all our serialization needs.
|
Streaming application
Then create the following file at /src/main/kotlin/io/confluent/developer/kstreams/RunningAverage.kt.
Let’s take a close look at the buildTopology() method, which uses the Kafka Streams DSL.
import com.typesafe.config.Config
import com.typesafe.config.ConfigFactory
import io.confluent.developer.ktor.*
import io.confluent.kafka.schemaregistry.client.SchemaRegistryClientConfig.BASIC_AUTH_CREDENTIALS_SOURCE
import io.confluent.kafka.schemaregistry.client.SchemaRegistryClientConfig.USER_INFO_CONFIG
import io.confluent.kafka.streams.serdes.json.KafkaJsonSchemaSerde
import io.ktor.application.*
import io.ktor.server.netty.*
import org.apache.kafka.common.serialization.Serdes.*
import org.apache.kafka.common.utils.Bytes
import org.apache.kafka.streams.KafkaStreams
import org.apache.kafka.streams.KeyValue
import org.apache.kafka.streams.StreamsBuilder
import org.apache.kafka.streams.Topology
import org.apache.kafka.streams.kstream.*
import org.apache.kafka.streams.kstream.Grouped.with
import org.apache.kafka.streams.state.KeyValueStore
import java.io.File
import java.time.Duration
import java.util.*
const val ratingTopicName = "ratings"
const val ratingsAvgTopicName = "rating-averages"
fun Application.module(testing: Boolean = false) {
lateinit var streams: KafkaStreams
// load properties
val kafkaConfigPath = "src/main/resources/kafka.conf"
val config: Config = ConfigFactory.parseFile(File(kafkaConfigPath))
val properties = effectiveStreamProperties(config)
//region Kafka
install(Kafka) {
configurationPath = kafkaConfigPath
topics = listOf(
newTopic(ratingTopicName) {
partitions = 3
//replicas = 1 // for docker
replicas = 3 // for cloud
},
newTopic(ratingsAvgTopicName) {
partitions = 3
//replicas = 1 // for docker
replicas = 3 // for cloud
}
)
}
//endregion
val streamsBuilder = StreamsBuilder()
val topology = buildTopology(streamsBuilder, properties)
//(topology.describe().toString())
streams = streams(topology, config)
environment.monitor.subscribe(ApplicationStarted) {
streams.cleanUp()
streams.start()
log.info("Kafka Streams app is ready to roll...")
}
environment.monitor.subscribe(ApplicationStopped) {
log.info("Time to clean up...")
streams.close(Duration.ofSeconds(5))
}
}
fun buildTopology( builder: StreamsBuilder, properties: Properties ): Topology {
val ratingStream: KStream<Long, Rating> = ratingsStream(builder, properties)
getRatingAverageTable(
ratingStream,
ratingsAvgTopicName,
jsonSchemaSerde(properties, false)
)
return builder.build()
}
fun ratingsStream(builder: StreamsBuilder, properties: Properties): KStream<Long, Rating> {
return builder.stream( ratingTopicName, Consumed.with(Long(), jsonSchemaSerde(properties, false)) ) }
fun getRatingAverageTable( ratings: KStream<Long, Rating>, avgRatingsTopicName: String, countAndSumSerde: KafkaJsonSchemaSerde<CountAndSum> ): KTable<Long, Double> {
// Grouping Ratings
val ratingsById: KGroupedStream<Long, Double> = ratings
.map { _, rating -> KeyValue(rating.movieId, rating.rating) }
.groupByKey(with(Long(), Double()))
val ratingCountAndSum: KTable<Long, CountAndSum> = ratingsById.aggregate(
{ CountAndSum(0L, 0.0) },
{ _, value, aggregate ->
aggregate.count = aggregate.count + 1
aggregate.sum = aggregate.sum + value
aggregate
},
Materialized.with(Long(), countAndSumSerde)
)
val ratingAverage: KTable<Long, Double> = ratingCountAndSum.mapValues(
{ value -> value.sum.div(value.count) },
Materialized.`as`<Long, Double, KeyValueStore<Bytes, ByteArray>>("average-ratings")
.withKeySerde(LongSerde())
.withValueSerde(DoubleSerde())
)
// persist the result in topic
val stream = ratingAverage.toStream()
//stream.peek { key, value -> println("$key:$value") }
stream.to(avgRatingsTopicName, producedWith<Long, Double>())
return ratingAverage
}
inline fun <reified V> jsonSchemaSerde( properties: Properties, isKeySerde: Boolean ): KafkaJsonSchemaSerde<V> {
val schemaSerde = KafkaJsonSchemaSerde(V::class.java)
val crSource = properties[BASIC_AUTH_CREDENTIALS_SOURCE]
val uiConfig = properties[USER_INFO_CONFIG]
val map = mutableMapOf(
"schema.registry.url" to properties["schema.registry.url"]
)
crSource?.let {
map[BASIC_AUTH_CREDENTIALS_SOURCE] = crSource
}
uiConfig?.let {
map[USER_INFO_CONFIG] = uiConfig
}
schemaSerde.configure(map, isKeySerde)
return schemaSerde;
}To calculate the running average, we need to capture the sum of ratings and counts as part of the same aggregating operation.
<count,sum> tuple as aggregation result values.val ratingCountAndSum: KTable<Long, CountAndSum> = ratingsById.aggregate(
{ CountAndSum(0L, 0.0) },
{ _, value, aggregate ->
aggregate.count = aggregate.count + 1
aggregate.sum = aggregate.sum + value
aggregate
},
Materialized.with(Long(), countAndSumSerde)
)val ratingAverage: KTable<Long, Double> = ratingCountAndSum.mapValues(
{ value -> value.sum.div(value.count) },
Materialized.`as`<Long, Double, KeyValueStore<Bytes, ByteArray>>("average-ratings")
.withKeySerde(LongSerde())
.withValueSerde(DoubleSerde())
)This pattern can also be applied to compute a windowed average or to compose other functions.
Now create the following file at src/test/kotlin/io/confluent/developer/RunningAverageTest.kt.
Testing a Kafka streams application requires a bit of test harness code, but happily the org.apache.kafka.streams.TopologyTestDriver class makes this much more pleasant that it would otherwise be.
There is a validateAverageRating() method in RunningAverageTest annotated with @Test.
This method actually runs our Streams topology using the TopologyTestDriver and some mocked data that is set up inside the test method.
import io.confluent.developer.kstreams.*
import io.confluent.kafka.streams.serdes.json.KafkaJsonSchemaSerde
import org.apache.kafka.common.serialization.DoubleDeserializer
import org.apache.kafka.common.serialization.LongDeserializer
import org.apache.kafka.common.serialization.LongSerializer
import org.apache.kafka.streams.*
import org.apache.kafka.streams.kstream.KStream
import org.apache.kafka.streams.state.KeyValueStore
import org.hamcrest.CoreMatchers
import org.hamcrest.MatcherAssert
import org.junit.After
import org.junit.Assert
import org.junit.Before
import org.junit.Test
import java.util.*
class RunningAverageTest {
private lateinit var testDriver: TopologyTestDriver
private var ratingSpecificAvroSerde: KafkaJsonSchemaSerde<Rating>? = null
@Before
fun setUp() {
val mockProps = Properties()
mockProps["application.id"] = "kafka-movies-test"
mockProps["bootstrap.servers"] = "DUMMY_KAFKA_CONFLUENT_CLOUD_9092"
mockProps["schema.registry.url"] = "mock://DUMMY_SR_CONFLUENT_CLOUD_8080"
val builder = StreamsBuilder()
val countAndSumSerde: KafkaJsonSchemaSerde<CountAndSum> = jsonSchemaSerde(mockProps, false)
ratingSpecificAvroSerde = jsonSchemaSerde(mockProps, false)
val ratingStream: KStream<Long, Rating> = ratingsStream(builder, mockProps)
getRatingAverageTable(
ratingStream,
AVERAGE_RATINGS_TOPIC_NAME,
countAndSumSerde
)
val topology = builder.build()
testDriver = TopologyTestDriver(topology, mockProps)
}
@Test
fun validateIfTestDriverCreated() {
Assert.assertNotNull(testDriver)
}
@Test
fun validateAverageRating() {
val inputTopic: TestInputTopic<Long, Rating> = testDriver.createInputTopic(
RATINGS_TOPIC_NAME,
LongSerializer(),
ratingSpecificAvroSerde?.serializer()
)
inputTopic.pipeKeyValueList(
listOf(
KeyValue(LETHAL_WEAPON_RATING_8.movieId, LETHAL_WEAPON_RATING_8),
KeyValue(LETHAL_WEAPON_RATING_10.movieId, LETHAL_WEAPON_RATING_10)
)
)
val outputTopic: TestOutputTopic<Long, Double> = testDriver.createOutputTopic(
AVERAGE_RATINGS_TOPIC_NAME,
LongDeserializer(),
DoubleDeserializer()
)
val keyValues: List<KeyValue<Long, Double>> = outputTopic.readKeyValuesToList()
// I sent two records to input topic
// I expect second record in topic will contain correct result
val longDoubleKeyValue = keyValues[1]
println("longDoubleKeyValue = $longDoubleKeyValue")
MatcherAssert.assertThat(
longDoubleKeyValue,
CoreMatchers.equalTo(KeyValue(362L, 9.0))
)
val keyValueStore: KeyValueStore<Long, Double> = testDriver.getKeyValueStore("average-ratings")
val expected = keyValueStore[362L]
Assert.assertEquals("Message", expected, 9.0, 0.0)
}
@After
fun tearDown() {
testDriver.close()
}
companion object {
private const val RATINGS_TOPIC_NAME = "ratings"
private const val AVERAGE_RATINGS_TOPIC_NAME = "average-ratings"
private val LETHAL_WEAPON_RATING_10 = Rating(362L, 10.0)
private val LETHAL_WEAPON_RATING_8 = Rating(362L, 8.0)
}
}Infrastructure
version: '2'
services:
zookeeper:
image: confluentinc/cp-zookeeper:6.0.0
hostname: zookeeper
container_name: zookeeper
ports:
- "2181:2181"
environment:
ZOOKEEPER_CLIENT_PORT: 2181
ZOOKEEPER_TICK_TIME: 2000
broker:
image: confluentinc/cp-kafka:6.0.0
hostname: broker
container_name: broker
depends_on:
- zookeeper
ports:
- "29092:29092"
environment:
KAFKA_BROKER_ID: 1
KAFKA_ZOOKEEPER_CONNECT: 'zookeeper:2181'
KAFKA_LISTENER_SECURITY_PROTOCOL_MAP: PLAINTEXT:PLAINTEXT,PLAINTEXT_HOST:PLAINTEXT
KAFKA_ADVERTISED_LISTENERS: PLAINTEXT://broker:9092,PLAINTEXT_HOST://localhost:29092
KAFKA_OFFSETS_TOPIC_REPLICATION_FACTOR: 1
KAFKA_GROUP_INITIAL_REBALANCE_DELAY_MS: 0
KAFKA_TOOLS_LOG4J_LOGLEVEL: ERROR
schema-registry:
image: confluentinc/cp-schema-registry:6.0.0
hostname: schema-registry
container_name: schema-registry
depends_on:
- broker
ports:
- "8081:8081"
environment:
SCHEMA_REGISTRY_HOST_NAME: schema-registry
SCHEMA_REGISTRY_KAFKASTORE_BOOTSTRAP_SERVERS: 'broker:9092'
SCHEMA_REGISTRY_LOG4J_ROOT_LOGLEVEL: WARN